Marvelous Info About What Is BOM In UTF
What's This BOM Thing in UTF All About?
1. Unveiling the Mystery of BOM
Ever stumbled upon a weird character at the beginning of a text file and wondered where it came from? Chances are, you've met the BOM, or Byte Order Mark. Now, that sounds intimidating, right? Like something out of a spy movie. But trust me, it's not that scary. It's actually a helpful little thing that tells computers how to read the characters in a file, especially when we're talking about different Unicode encodings.
Think of it like this: you're sending a secret message, and the BOM is the key to decoding it. Its a sequence of bytes that sit at the very start of the file, acting as a kind of signature. It identifies the file as using a particular Unicode encoding, such as UTF-8, UTF-16, or UTF-32. It helps programs correctly interpret the characters, so you don't end up with gibberish instead of meaningful text.
Without the BOM, programs would have to guess the encoding, which could lead to errors. Imagine trying to read a book written in a language you don't understand — chaos! The BOM prevents that chaos, making sure everyone's on the same page, so to speak. It's all about smooth communication between computers and software.
So, in short, the BOM is there to save the day, ensuring your text displays correctly across different platforms and applications. It's a small but mighty detail in the world of text encoding, making our digital lives just a little bit easier. Now, let's dive a bit deeper into why it exists and where it's particularly useful.

Why Does This BOM Even Exist?
2. Decoding the Reasoning Behind BOM
Alright, let's get to the core of the issue: why did someone invent the BOM in the first place? Well, back in the early days of computing, character encoding was a bit of a Wild West. Different systems used different ways of representing characters, and things got messy fast. Unicode came along to standardize things, but even within Unicode, there were different ways of arranging the bytes that represent characters — particularly in encodings like UTF-16 and UTF-32.
This byte order issue is where the BOM really shines. For UTF-16 and UTF-32, the order of bytes matters. Some systems read bytes from left to right (big-endian), while others read them from right to left (little-endian). Without a way to signal which order is being used, the same file could be interpreted completely differently on different machines. Its like trying to assemble furniture with instructions written in a mirror — frustrating and probably resulting in something wonky.
So, the BOM steps in to clarify things. By placing a specific byte sequence at the beginning of the file, it tells the reading program which byte order to expect. This ensures that characters are interpreted correctly, regardless of the system being used. It's all about avoiding the dreaded "mojibake," that garbled text that appears when the encoding is wrong. Thats no fun for anyone!
The BOM isn't always necessary, especially with UTF-8, because UTF-8's byte order is always the same. However, even with UTF-8, a BOM can be used to explicitly mark the file as UTF-8 encoded. Some older software might rely on this marker to correctly identify the encoding. Think of it as being polite and saying, "Hey, I'm UTF-8!" even if it's pretty obvious. Its just good manners in the digital world!

Convert Encoding From UTF8 With BOM Studio UiPath Community
UTF-8 and BOM
3. Navigating the UTF-8 BOM Landscape
Now, let's talk about UTF-8 and the BOM. As mentioned earlier, UTF-8 doesn't actually need a BOM to indicate byte order because its byte order is fixed. So, why would you ever use a BOM with UTF-8? That's a great question! The main reason is to explicitly declare that a file is encoded in UTF-8.
Some older text editors and software applications might have trouble automatically detecting UTF-8 encoding. In these cases, the presence of a BOM can help them correctly interpret the file. Think of it as adding a little label to your food container in the fridge — even if it's obvious what's inside, it's a nice gesture that can prevent confusion.
However, there's also a downside to using a BOM with UTF-8. Some other software, particularly in the Unix/Linux world, might not expect a BOM in UTF-8 files and can misinterpret it as part of the actual content. This can lead to the dreaded "extra character" appearing at the beginning of the text — usually a weird symbol that wasn't supposed to be there. It can be annoying and cause problems with scripts and programs that rely on the exact content of the file.
Therefore, the decision to use a BOM with UTF-8 is a bit of a balancing act. It depends on the specific software you're using and the audience you're targeting. In general, it's often best to avoid using a BOM with UTF-8 unless you have a specific reason to include it. It's like wearing a hat indoors — sometimes it's necessary, but most of the time it's just going to make things awkward.
BOM's Impact on Web Development
4. BOM's Role in Web Environment
So, how does this BOM thing affect web development? Well, when it comes to web pages and web applications, the BOM can sometimes cause headaches if not handled properly. Imagine you're building a website, and your HTML, CSS, or JavaScript files have a BOM. If your web server or browser misinterprets that BOM, it can lead to rendering issues, JavaScript errors, or other unexpected behavior.
For example, if your JavaScript file has a UTF-8 BOM and the browser doesn't correctly handle it, you might see an extra character at the beginning of your script, which can break your code. Similarly, if your CSS file has a BOM, it could mess up your styling. It's like adding a typo to your recipe — it might not ruin the whole dish, but it can definitely throw things off.
To avoid these issues, it's generally best practice to save your web development files without a BOM, especially when using UTF-8. Most modern text editors provide options to save files in UTF-8 "without BOM," which is the preferred choice for web development. Its like making sure your ingredients are fresh and properly measured before you start cooking — it helps ensure a smooth and successful outcome.
Additionally, it's important to configure your web server to serve files with the correct character encoding. This can be done by setting the "Content-Type" header in the HTTP response. This header tells the browser what encoding to use when interpreting the file. It's like adding a label to your finished dish, telling everyone what they're about to eat. This helps avoid any confusion and ensures that your website displays correctly for everyone.

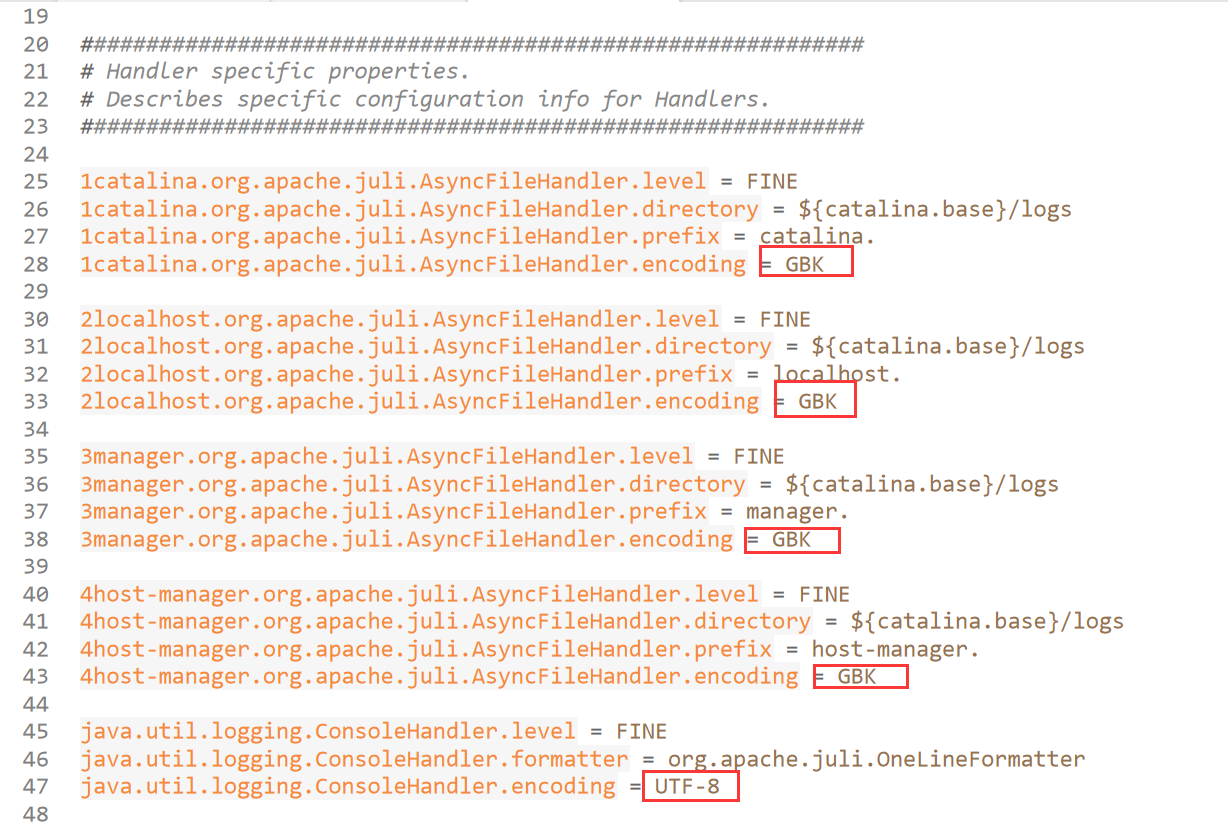
BOM
5. Weighing the Pros and Cons of BOM
So, is the BOM a friend or a foe? Well, like many things in the world of technology, it's a bit of both. In some situations, it's a helpful tool that ensures correct character encoding and prevents errors. In other situations, it can cause problems and lead to unexpected behavior. It's like a Swiss Army knife — incredibly useful in the right circumstances, but potentially dangerous if used improperly.
The key is to understand how the BOM works and when it's appropriate to use it. For UTF-16 and UTF-32, the BOM is generally necessary to indicate byte order. For UTF-8, it's often best to avoid it unless you have a specific reason to include it. It's all about making informed decisions based on your specific needs and the software you're using.
Ultimately, the goal is to ensure that your text displays correctly across different platforms and applications. By understanding the BOM and its implications, you can avoid encoding issues and create a smoother, more consistent user experience. It's like being a responsible chef — knowing your ingredients and how they interact with each other to create a delicious and harmonious dish.
So, next time you encounter a BOM, don't be afraid. Instead, take a deep breath, remember what you've learned here, and make an informed decision about how to handle it. You've got this! And who knows, you might even impress your friends with your newfound knowledge of character encoding. Just try not to bore them too much!
Frequently Asked Questions (FAQ)
6. Your Burning BOM Questions Answered
Still scratching your head about BOM? No worries! Let's tackle some common questions:
Q: How do I remove a BOM from a file?
A: Many text editors offer an option to save files in UTF-8 "without BOM." Look for this option in the "Save As" dialog. Alternatively, you can use command-line tools like `iconv` (on Linux/macOS) to convert the file to UTF-8 without BOM. Its like decluttering your digital space — getting rid of unnecessary baggage!
Q: Does the BOM affect file size?
A: Yes, the BOM adds a few bytes to the beginning of the file (typically 2-3 bytes). This increase is usually negligible for larger files, but it can be noticeable for very small files. Think of it as adding a tiny sprinkle of seasoning to your dish — it adds a little bit, but its not going to drastically change the overall size.
Q: What happens if I open a file with the wrong encoding?
A: If you open a file with the wrong encoding, you'll likely see garbled text or strange characters. This is because the program is misinterpreting the bytes in the file. To fix this, try opening the file with a different encoding setting in your text editor. Its like trying on shoes that are the wrong size — uncomfortable and not a good fit. You need to find the right encoding shoe!